
2.输入输出设备模型
有了存储设备,如何把这个设备“接到”电脑上?
这部分内容
I/O 设备原理、构造与实现
总线、中断控制器和 DMA
GPU 和加速器
1. 输入输出设备原理
当我们谈计算机的时候,我们使用的输入输出设备。第一次遇到计算机,看的时显示器,用的是鼠标键盘。而去学习计算机的时候,如计算机组成原理,学的是如何造一个 CPU。
回顾 CPU ,取指令,译码,执行。我们用的东西并不是计算机里做运算的最核心的设备。我们用的是输入输出设备,设个设备是一定要和 CPU 做数据交互的。
如果我们想为任何一个 CPU 实现一个 IO 设备,那这个 IO 设备和 CPU 应该是怎么合作的呢?看一个具体的例子,从这个例子推演其他设备是如果接入的。
答案,连一根线就行,用数字逻辑电路实现,我们直接把线连到外面去,在 CPU 里增加两条指令,read_key,read_button,这就把设备接到计算机系统里了(微机原理,轮询,电路)。所以把设备接入计算机系统的方式,一组线 + 指令。
所以对 CPU 来说,谈输入输出设备原理的时候,就是一根线,用约定好的方式交换数据,就这样。比如说 LDR STR 读的不再是内存,而是读的一个引脚的值。
有的计算机系统如嵌入式系统,有的脚叫 GPIO,极简的模型 memory-mapped IO,直接读写电平信号。CPU 并不关心连到线上的是 DDR 还是什么。完全可以在 地址线上挂一个东西,在某个地址范围内直接转发到某个设备上。然后直接用 LDR STR 来操作一个 GPIO。
但是如果各种各样的设备,都拉线,那么整个计算机系统就会变得相当复杂。实际上对 IO 设备是有抽象的,对任何一个 IO 设备,都抽象成寄存器集合,如果给寄存器编上地址的话,还可以映射到一个地址空间里,映射到内存地址、IO地址都可以做到和 CPU 交换数据。
具体来说,有这些类型的寄存器
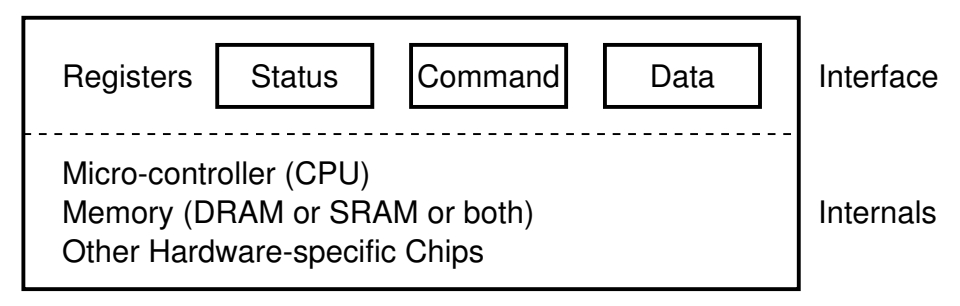
状态来查询,一般只读,命令寄存器一般只写,数据寄存器能读能写。
不管设备后面多复杂,可能有一个完整的计算机系统,如 SSD,还是可以抽象成这个样子,即询问硬盘状态,然后给命令控制,读写数据。
即把任何设备都抽象成这样的“约定好功能的线”,把寄存器接到 CPU 上去。然后因为设备很多,CPU 不可能有太多的引脚,就需要编一个地址。有了地址,又该如何访问呢?可以像访问内存一样访问,memory 本身也可以看成好多寄存器,为什么不把设备的寄存器看成内存呢?这就是内存映射IO,memory mapped io(MMIO),这个想法也很简单,我们希望把设备寄存器映射到内存地址上,在硬件做一点小小的操作就行。这样的话,我们不需要增加新的指令,就直接用 load和 store 指令就行。
x86 的专门的操作设备的指令 IN OUT,相当于专门为设备开辟了一个地址空间。但是本质上就是 load store。从此以后,CPU 不用管那个设备映射到那个地址,只要软件知道就行,比如linux内核知道pci总线在哪个地址,显存在哪个地址。只要软件知道地址在哪里就行,硬件不用管了。
例子 (1): 串口 (UART)
一个具体的例子,实验框架串口的实现,x86是一个分别的地址空间,COM1 的地址是 0x3f8,如果想访问的话,先要问端口。这些都是硬件上的控制器相关细节,如果将来从事硬件驱动开发,否则这些细节对于操作系统本身没多大影响,看手册就行,所有的设备都是这个模型。
#define COM1 0x3f8
static int uart_init() {
outb(COM1 + 2, 0); // 控制器相关细节
outb(COM1 + 3, 0x80);
outb(COM1 + 0, 115200 / 9600);
...
}
static void uart_tx(AM_UART_TX_T *send) {
outb(COM1, send->data);
}
static void uart_rx(AM_UART_RX_T *recv) {
recv->data = (inb(COM1 + 5) & 0x1) ? inb(COM1) : -1;
}例子 (2): 键盘控制器
除此之外,另一个例子,键盘控制器,我们身边的东西,是如何工作的?IBM PC 老式的接口 PS/2 接口,硬编码了两个 IO 地址空间的地址,0x60 (data), 0x64 (status/command)
60是键盘的数据,这么一个简单的键盘,控制还是挺丰富的,
0xED
LED 灯控
ScrollLock/NumLock/CapsLock
0xF3
设置重复速度
30Hz - 2Hz; Delay: 250 - 1000ms
0xF4/0xF5
打开/关闭
N/A
0xFE
重新发送
N/A
0xFF
RESET
N/A
三个键盘灯是可以用软件来控制的,这个协议也规定了这些。包括键盘的重复速度,硬件承担了这个功能,可以配置这些属性(现在 CPU 能力强了,这个功能可以在软件上做,不是特别的计算密集型任务,软件实现更加灵活)。
例子 (3): 磁盘控制器
磁盘,这部分的主线内容。
早期的磁盘接口,ATA 时代不支持热插拔,磁盘的抽象还是数组,这个数组以扇区(sector)为单位,512Byte,所以 legacy boot 里读第一个扇区即 512 字节。
IBM PC 里面可以放两块磁盘,0x1f0-0x1f7第一块磁盘,0x170-0x177第一块磁盘。
如果想要读一个扇区的话,用下面的代码
void readsect(void *dst, int sect) {
waitdisk();
out_byte(0x1f2, 1); // sector count (1)
out_byte(0x1f3, sect); // sector
out_byte(0x1f4, sect >> 8); // cylinder (low)
out_byte(0x1f5, sect >> 16); // cylinder (high)
out_byte(0x1f6, (sect >> 24) | 0xe0); // drive
out_byte(0x1f7, 0x20); // command (write)
waitdisk();
for (int i = 0; i < SECTSIZE / 4; i ++)
((uint32_t *)dst)[i] = in_long(0x1f0); // data
}等待磁盘就绪,然后按照磁盘的手册,把控制命令写进入,直接读就可以了。
例子 (4): 打印机
把字节流描述的文字/图形打印到纸张上。
打印机是另一个带 CPU 的设备。
计算机里的设备?
早期的计算机,厂商必须告诉操作系统,什么设备在什么地址。
现在的 linux ,有 device tree 的机制。
可以通过 dtc,查看每个设备是放在哪里的。
2. 管理更多的 IO 设备
总线、中断控制器和 DMA
总线
如果只造一台计算机的话,都好说,随便给每个设备定一个端口/地址,连接到 CPU 就行,自制 CPU 会这么干,(MCU 也会这么干,单片微型计算机,里面的IO设备都做死了,地址也都给死了),这就把整个系统限制死了,但是如果想给未来留点空间?
以及,现在越来越复杂的个人计算机?想未来接入未知的设备,如新型打印机,游戏方向盘,这样的设备来了以后应该怎么办呢?
当系统有扩展空间的时候,就发明了总线。做一个特殊的 IO 设备,这个设备把其他 IO 设备都管起来。
CPU 不需要直接看到所有的设备,像 IBMPC 规定的,每个设备在固定的位置。总线上除了连设备,甚至还可以连接别的总线控制器,总线把所有的IO设备统一管理起来,CPU 想访问一个设备的时候,只要把这个设备在总线上的地址告诉总线,相应的就可以把数据由总线分发到设备上,如果总线上的设备都想向CPU发送一个中断的话,总线也会协调中断,发送优先级高的,甚至CPU可以问总线是哪个设备发生了中断。
总线可以理解为一个特殊的 IO 设备,提供设备的注册和地址到设备的转发。注册是很重要的,IBMPC 不支持热插拔,总线上可以做一个协议规范,如果一个设备支持热插拔,应该给总线发一个什么样的信号。总线以某种方式告诉处理器如中断。
总线就是一个协议,约定了、规范了设备如果以一个总线的方式来实现,就可以更好的方式管理起来,接入到计算机系统。总线上的地址到设备的转发,CPU 不管以哪种方式(可能还是memory mapped io,比如pci),写入,总线会转发到上面的设备。
比如 x86 的 io 端口地址就是 IO 总线上的地址,所以 IBMPC 的 CPU 其实只看了这一个 IO 设备。
这样 CPU 只需要直连一个总线就行了。今天 PCI 总线肩负了这个任务,PCI 总线可以桥接其他总线,如 PCI->USB,指令 lspci,能看到,速度快的设备直接挂在 PCI 总线上,比如说买一个 CPU,有个参数是 PCI 通道数,数量多以为着能用更快的速度传输数据。网卡也会直接挂在 PCI 总线上,NVME 的 SSD 最后也会接到 PCI 总线上。
PCI 会桥接 USB、SATA 等总线控制器。相比于 PCI,USB 总线的速度还是比较低的,lsusb -tv 可以查看系统总线上的设备。
总线的概念还是比较简单的,但是实际很复杂。要规定很多细节,如电气特性、中断如何送到,如何仲裁,Plug and Play,win98的著名发布会翻车。许多的复杂机制,
这些规范就是大厂坐下来讨论出来的一个规范。这些也不是操作系统的内容,和驱动开发走的比较近。
中断控制器
计算机另一个比较特别的设备,中断控制器。为何应用程序的 while(1); 不会卡死 CPU 呢?因为真的有个线连在了 CPU 上,上古CPU 6502 有个脚 ,所以从这个角度说操作系统启动就就变成了中断处理程序。
Intel 的中断控制器,8259A,中断控制器同样控制寄存器、数据寄存器。CPU 去用 load store 指令交换一些信息。很多设备都可以产生中断,如键盘、鼠标、网卡,每个中断源都有一根线,接到8259A上,这是个可编程设备。
现在的 CPU ,8259A 已经无法满足了,现在又两类,APIC(advanced),IOPIC,(programmable interrupt controller)
local APIC: 中断向量表, IPI, 时钟,
I/O APIC: 其他 I/O 设备
LAPIC 还有一个重要的功能是向其他 CPU 发送中断,比如说 CPU 启动时,第一个 CPU 启动后,让其他 CPU 启动,就会发送中断。还有一个 mmap 和 unmmap 系统调用,CPU1 和 CPU2 同时运行了一个进程的两个线程,看到的同一个地址空间,如果在一个 CPU 上执行了 munmap ,另一个 CPU 上的线程也是不可以访问的,操作系统是知道线程在两个 CPU 上运行的,会执行一个 TLB shoot down,以核间中断的方式通知,消除映射。
有了总线和中断控制器以后,得到了和现代 CPU 非常接近的模型。
DMA
但是中断和IO指令都没有解决传输大量数据的问题。这也是一个合理的需求。假设程序希望写入 1GB 数据到磁盘,即便磁盘是准备好的。数据需要总线上绕一圈,这就慢了。搬动数据这种重复的活,
for (int i=0; i<1GB/4; i++)
{
outl(PORT, ((u32*)buf)[i]);
}既然需求是把内存里的一块搬到 IO 设备里,那么有没有可能从循环的代码解放出来?即专门有一个小的 CPU,只能执行搬数据的功能。这样的话,这个 CPU 就可以做的很简单,甚至把 memory 的指令直接硬编码到电路上,把 CPU 从这个事情里解放出来(事实上,计算机系统里这样的设计到处都是)
专门用来执行 memcpy 的 CPU,可以实现的功能
memory → memory
memory → device (register)
device (register) → memory
这就是 DMA 控制器,直接连接在总线和内存上。典型的芯片 Intel 8237A。
现在的 PCI 总线就是支持 DMA 的,使用 sudo cat /proc/iomem 可以看到整个 PCI 总线设备都是 memory mapped io 的。iomem 就是总线和 内存控制器共同能够看到的地址空间,如 System RAM 。所以加一个 memory copy CPU 就能实现数据在两者传统,现在的 PCI 总线都自带支持 DMA 传输,现在的网卡、显卡等设备,都是通过 DMA 在内存和设备之间传输数据。(高速、大量数据)
现在的电脑支持总线 DMA,比如网卡可以直接不经过CPU写内存。写好通知CPU取数据。
3. 填补 CPU 的算力空白
GPU 和异构计算
另一个有意思的问题,什么是显卡?
其实 IO设备 和计算机的边界是很模糊的。打印机就是一个解释执行一个程序的 CPU,DMA 就是一个专用 CPU,每个CPU擅长的事情都不一样,比如 x86 CPU是个集成度很高的通用CPU,擅长做通用计算,拿来做 DMA 就太浪费了,包括像打印机的 CPU 不需要太好。因此我们就可以在计算机系统里加一个CPU做特定的事情。
显卡就是这么来的。
大一刚学编程的时候,输出各种字符画。
for (int i = 1; i <= H; i++) {
for (int j = 1; j <= W; j++)
putchar(j <= i ? '*' : ' ');
putchar('\n');
}但是,如果想在 4K 屏幕上画彩色图形,就不是很容易了。CPU 跟不上显示的速度这个问题由来已久。
早在任天堂 NES 的年代,CPU 是 6502 芯片,1.79Mhz,IPC=0.43(现代CPU大于1,每个周期执行小于1条指令),不像现在的CPU乱序执行。可是居然做到了在屏幕上显示 256*240=61k 像素(256色)。而且 60fps 显示,非常丝滑,每一帧只给 10k 条指令,10k 条指令执行 61k 个 nop 都不行,更别说去总线上搬东西了。这个问题就是如何在有限的 CPU 运算力下实现 60Hz。
打印机给了启发,用文本描述要画什么,然后打印机去完善细节,一段描述的文本变成高清矢量的图形。
当时的聪明工程师,想到了和 DMA 一样的设计,增加一个小 CPU,这个设备只能用来画图,但是画的超级快。这就是 NES 的 Picture Processing Unit(PPU)。
CPU 只描述 8*8 方块的摆放方法。

CPU 把需要画什么内容告诉 PPU,显卡就去负责具体每个像素的计算和显示。显卡和前面那个二重循环一样,很简单的程序,但是很多,去并行计算。
NES PPU 的本质还是坐标轴平行去贴块。实现上只需要加法和位运算。如果我们有更多的晶体管,就可以做更复杂的事情,比如 2D 图形加速硬件可以实现图片的裁剪和拼贴,旋转、映射。更强大的计算能力 = 更复杂的图形绘制。
甚至在2D时代,也可以实现以假乱真的3D。

但我们还是需要真正的实现3D,三角形分割,投影、计算。一个定理:任何 n 边形都可以分解成 n-2 个三角形,这时候需要建模的东西更多
几何、材质、贴图、光源、……
Rendering pipeline 里大部分操作都是 massive parallel 的
光源是个很麻烦的事情,这就有了 光线追踪。每个像素的处理都是独立的,这就意味可以为每个像素分配一个单独的CPU,并行起来处理,让现在的游戏有更真实的表现。

题外话:如此丰富的图形是怎么来的?
全靠 PS,(后处理),GLSL
GLSL (Shading Language)
使 “shader program” 可以在 GPU 上执行
可以作用在各个渲染级别上:vertex, fragment, pixel shade
相当于一个 “PS” 程序,算出每个部分的光照变化全局光照、反射、阴影、环境光遮罩……

现在的显卡已经不仅仅是显卡了,现代的 GPU 不仅仅可以做这么复杂的光线运算,也可以用来做矩阵计算。上面有许多并行CPU,有VRAM,CPU可以通过DMA把数据送到VRAM,然后开始大规模进行运算。CUDA、有了显卡上的通用计算。
如果写过显卡的程序,nvcc(基于LLVM修改的),nvcc会把程序分成两部分,main函数编译/链接成本地可执行的 ELF,显卡上执行的部分编译成 GPU 指令 (PTX; 送给驱动),看手册,显卡的汇编,显卡的编程模型,和 x86 编程没有本质的区别。甚至在一条指令中可以执行矩阵运算,把算好的东西直接给视频接口。也可以通过 DMA 传回系统内存。程序保存在内存 (显存) 中
main 编译/链接成本地可执行的 ELF
kernel 编译成 GPU 指令 (送给驱动)
GPU就是一个有好多好多 CPU 的系统比如 4096CPU,CPU 把 GPU 需要的数据通过 DMA 送到显存里,然后把 code 也送到显存里。然后就可以执行了,执行完给 CPU 发个中断。GPU 既可以看成 IO 设备,也可以看成另一台计算机。如果是玩游戏的话,GPU还会把像素算出来,推给视频接口。
通用计算的例子,PyTorch 和炼丹炉。
什么是深度神经网络?
逻辑不难,代码不多,的重复运算。难点在于参数特别多。
到今天,Dark Silicon Age 和异构计算,功耗成为了瓶颈。能完成 “同一件事” 的部件可能有很多,要选择功耗/性能/时间最合适的那个!事实上 GPU 跑神经网络能效比都很低,用NPU。
如果将来狂潮来了,手机上的 SoC,可以集成 CPU,GPU,NPU,矿PU,,一个SoC的功耗就这么大,来任务以后选择能效比最高的来计算。
总结
从uart到GPU。
IO设备就是一组交换数据的接口和协议。
如果你 “自己造一台计算机”,你会发现这一切都是自然的。
“不容易理解” 的部分是随时间积累的复杂性。
一个完整的计算机系统,NES 6502.
最后更新于
这有帮助吗?