
4.文件系统 API
回顾。
器件,物理世界保存 1bit,磁带、磁盘、ssd。在存储设备的基础上,想用的话,还得努力。IO设备。io设备就是一些寄存器,在寄存器基础上操作系统又做了一些抽象,驱动层,可以读写控制的对象。对于持久化的存储设备,还有block的操作。
任何实现了 struct file_operations 的操作系统对象可以都是 “文件”:有驱动程序的设备;procfs 中的虚拟文件、管道……
操作系统将这些文件组织起来的方式:文件系统。
文件系统
很容易想到的是用一个树状目录去整理。
linux 对于文件系统的设计,一切东西都在 / 中。
但是麻烦的是非数据的文件,比如设备文件。ls / 里可以看到 dev 文件夹。这是 linux 的答案。都有东西都在 / 里。包括各种配置 如 Nginx 的配置,都是文件
windows 的设计,一个驱动器就是一棵树,C: D: E:。这也是一个很自然的设计,而且非常好理解,windows 里的配置有个机制注册表,巨大无比的配置文件。
windows 有一整套设备的 api 如 Windows Driver Model。
HANDLE hDevice = CreateFile(
"\\\\.\\PhysicalDrive0",
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ | FILE_SHARE_WRITE,
NULL, OPEN_EXISTING, 0, NULL
);unix 感觉到比较舒适的原因,设计时考虑了目录树的拼接。一个系统调用 mount,可以 man 2 mount 来查看。mount 命令是基于此实现的。
再看最小的linux,刚启动的时候,只有一个 busybox。但是运行 ps,会发现直接无法打开 /proc。如何把 procfs 放上去。直接 mkdir proc,然后 mount -t proc none /proc 指定文件系统类型和挂载目录。所有的东西就出来了。
unix 文件系统设计很灵活,这个机制可以让我们给不同的目录分不同的设备,这是区别windows每个磁盘一个根的设计。linux 安装的时候有 mount point,用一块比较快的盘做 / ,比较慢但容量大的盘做 /home。
mount 最神奇的一个应用,不仅仅可以挂载一个设备,还可以挂载一个文件系统里的文件。一个微妙的循环
文件 = 磁盘上的虚拟磁盘
挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘
比如挂载一个镜像。
linux 设计了 loop 回环设备。如果将一个镜像挂载了,lsblk 去查看的话就能看到多了一个 loop 设备。linux 做的事情,如果想把 .img 挂载,首先在操作系统里创建一个新的设备叫 loop ,和 img 关联起来,这两个是一个东西。文件系统要挂载的必须是一个存储设备,所以操作系统吧 img 虚拟成了一个 loop 设备,实际上挂载的是 loop 设备。
然后操作系统提供了一些文件系统 api 如 mkdir rmdir。
对于 rm 这个命令,事实上没有系统调用做删除这个事。strace 看的话调用的是 unlink 来做。
还有一个特性,需求:系统中可能有同一个运行库的多个版本
libc-2.27.so, libc-2.26.so
还需要一个 “当前版本的 libc”
程序需要链接 “libc.so.6”,可以复制一份需要的版本,然后改成这个名字
(硬)链接:允许一个文件被多个目录引用,举例 ln a b
不能连接目录,不能跨文件系统,完全相同的两个文件
删除文件的系统调用为 unlink
这个特性文件系统实现的一部分,所以不能跨文件系统
另一种,符号链接,类似快捷方式。软连接,跳转提示
允许一个文件被多个目录引用
当引用这个文件时,去找另一个文件
另一个文件的绝对/相对路径以文本形式存储在文件里
可以跨文件系统、可以链接目录、……
几乎没有任何限制
指向的位置不存在也行
文件系统的实现
如果想要实现一个文件系统,大概的思路。
文件系统里最核心的机制是 mount,意味着有一个设备,device,字节设备或块设备。把 device 和文件系统目录关联起来。
读写块设备的 API 就两个 读块,写块。
bread(int bid, struct block *b);
bwrite(int bid, struct block *b); 然后考虑如何实现出所有的文件系统 API。
read, write, ftruncate, ...
mkdir, rmdir, readdir, link, unlink, ...
文件系统里两个东西,一个是文件,一个是目录。
在块设备上模拟出 RAM 的感觉,会有严重的读写放大。所以需要考虑一个适合磁盘的数据结构。然后作为一个大的编程练习。
最大的问题是 读写放大。当然可以使用局部性和缓存来提高性能
适当地排布数据,使得临近的数据有 “一同访问” 的倾向
数据暂时停留在内存,延迟写回
fat 和 unix 文件系统
1980 年,软盘,360 个 512 Byte 扇区。在这样的设备上实现文件系统,对于数据结构的考虑
寸土寸金,一定要省空间,一般都是小文件,而且不会有太多内容,尽可能给多的空间到文件。高级的数据结构就是浪费,所以使用链表最合适。
目录的实现,目录也是一个普通的文件,操作系统对文件的内容作为目录解读,文件内容是一个线性表,指向文件位置就行。
用链表存储数据的两种设计
在每个数据块后放置指针
优点:实现简单、无须单独开辟存储空间
缺点:数据的大小不是 $ 2^k $ 单纯的 lseek 需要读整块数据
将指针集中存放在文件系统的某个区域
优点:局部性好;lseek 更快
缺点:集中存放的数据损坏将导致数据丢失
第一种方式的致命缺陷,修改一个文件的最后的一个字节,要把每块读出来但是只取指针,然后跳转下一块。
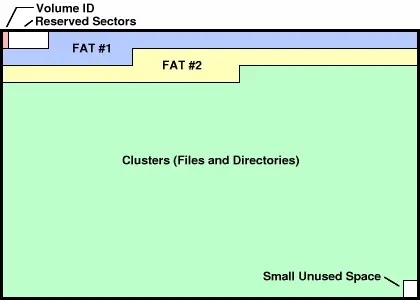
FAT 文件系统是第二种方案实现的。FAT12-16-32 代表了 next 指针的大小。32 bit
开头是基本信息,然后第一份指针,第二份指针做备份。后面是数据。
写代码实现一个 readfat,打开一个 fat 设备,然后用 mmap 映射到内存空间。然后看手册,如何解析这个数据结构。
手册里有相当具体的细节。
观察“快速格式化”是如何工作的 mkfs.fat,可以试着格式化一个文件。还是用 strace 来看。格式化的过程实际上就是写一大堆东西进去。
比如
cat /dev/zero | head --bytes 10240000 > file.img
mkfs.fat file.img
mount file.img /mnt然后就有了一个文件系统的镜像。
但是这个 fat 文件系统还是不太好,他适合小文件的存储。
如何设计一个对大文件更友好的数据结构?
对于小文件来说,用链表甚至用数组。next[10] 描述了 10 个块,不用遍历,一步到位。
大文件应该用树。
更好的设计,小文件用数组,大文件用树。全都考虑到了。
1. 文件系统
为什么要有文件系统
设备在应用程序之间共享。比如终端。4 个线程或者进程也可以,竞争同一个设备,输出数据到终端。如果使用的是 printf ,那效果符合我们的预期。也即 printf 打印字符串是有原子性的,这是库函数为我们提供的保证(太长了不行)。
如果使用了 putchar 的时候,我们担心的事情就发生了,互相抢设备,出现了乱七八糟的东西。设备在应用程序上共享是有难度的。
磁盘,block device,让所有的程序共享这个磁盘,有的要 write,有的要 read,该如何使用好磁盘呢?
终端作为字符设备,多线程一起 printf 还能接受,最多就是效果差点。但是磁盘,一起 write 是有可能覆盖其他有用的数据的。系统里各种各样的程序要管理各种各样的数据,用户数据、系统数据。
虽然应用程序数据就是字节序列。比如markdown,可以二进制查看,磁盘也是字节序列,可以 cat vda | head --bytes 512 | xxd 查看一个磁盘的前 512 bytes,顺便可以看到 55aa 的结尾。
但是字节序列并不是对磁盘好的抽象。
那该怎么办呢?
应用程序管理自己的数据,磁盘也是管理的数据,很自然的我们要把磁盘抽象为很多个虚拟磁盘。每个应用程序可以持有很多个虚拟磁盘,有一些是贡献的。
文件系统
文件系统:设计目标
提供合理的 API 使多个应用程序能共享数据
提供一定的隔离,使恶意/出错程序的伤害不能任意扩大
即要做“存储设备 (字节序列) 的虚拟化”
磁盘 (I/O 设备) = 一个可以读/写的字节序列
虚拟磁盘 (文件) = 一个可以读/写的动态字节序列 命名管理 虚拟磁盘的名称、检索和遍历 数据管理 std::vector (随机读写/resize)
其实也很简单,文件就是一个支持随机读写的字节序列。
文件系统下面是磁盘设备,文件系统里面有好多虚拟磁盘,文件系统最重要的一点是可以根据名字找到合适的文件。操作系统、应用程序都可以用一个合适的方式找到要使用的虚拟磁盘,就是这样。
文件系统就是个应用程序,可以不在操作系统课上讲。
文件系统和其他应用可以做进程间通信实现数据交换。
没有文件系统操作系统啥也干不了,深度绑定,所以还是在操作系统里学。前面学可执行文件,它放在哪里呢?存放在磁盘这个具体介质上,才能加载到内存里。
2. 文件系统的设计
虚拟磁盘:命名管理
如何在这么多文件中找到我们需要的那个。如一个游戏的过场动画,去哪里找。
最简单的实现就是每个文件都有一个独立的名字,key value,这种方式对遍历不太友好。
上百万个文件,如何更快的找呢?分类,比如图书馆。
找书,如果明确的知道这本书的名字,直接去找就好了。但是我们就是随便看看,找一个类型的,那么就去这个分类下的暑假去看就好了。不需要遍历整个图书馆的所有书。
这就是信息的局部性:将虚拟磁盘(文件)组织成层次结构。
目录树,逻辑相关的数据存放在相近的目录
.
└── 学习资料
├── .学习资料(隐藏)
├── 问题求解1
├── 问题求解2
├── 问题求解3
├── 问题求解4
└── 操作系统总有一个最大的目录。文件系统的根,根节点。
windows 每个设备(驱动器)是一棵树
C:\C盘根目录D:\u盘分配新的盘符
为什么没有
A:\B:\,挺好玩的事情。AB是软盘驱动器上的软盘。DOS时代的东西。现在软盘没了,但是兼容老设备。很简单粗暴方便,但是也有问题,如果 game.iso 光盘镜像为文件分盘符就费劲,
unix/linux
只有一个根
/所有的东西都在这里面。
那么U盘插进去怎么来的呢?
这个问题,如果建立起这个目录呢?
windows的每个设备是一个具体的字节序列,设备上的文件是虚拟出来的。
unix允许任意目录“挂载”一个设备代表的目录树。
一个存储设备,字节序列,用目录树里的一个目录来建立关系,这就是挂载。
文件的挂载引入了一个微妙的循环。
文件 = 磁盘上的虚拟磁盘
挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘 🤔
Linux 的处理方式,并不是直接挂载的
创建一个 loopback (回环) 设备
设备驱动把 loopback 设备的 read/write 转发到文件的 read/write
shell 里 lsblk 可以看到有 loop 设备。
可以用 strace 观察 disk-img.tar.gz 的挂载
查看 linux 所有的系统调用 man 2 syscalls 大概几百个,但是很多系统调用有相当丰富的语义,比如 ioctl,挂载的时候用了这个调用。
微软放弃了wsl1.0用api兼容的方式,因为一个ioctl就有千万行代码。要实现这个api,不可能。
windows有一个很直观的文件系统设备,一个驱动器是个文件系统,分类存放,C为系统,D为软件,E为数据。
linux 第一次接触时会很痛苦。每个目录还是缩写,搞不清楚含义。linux 并不是为 0 基础的人设计的,但是在正确的地方有一份好的手册,那么会对这个世界有更多的认识,能做更多的事。
在有文件系统的基础上,就可以去实现各种 api 了。
目录api (系统调用)
比如都用过的 mkdir,rmdir(只能删除一个空的目录),系统调用只提供了最基础的功能。
python 有更好用的api。如果不在意极限的性能的话。
from pathlib import Path
for f in Path('/proc').glob('*/status'):
print(f.parts[-2], \
(f.parent / 'cmdline').read_text() or '[kernel]')unix 里还有个有意思的实现。
链接
一个文件出现在不同的地方需要有不同的名字。这个需求是存在的。
如果一个动态库,要在不同地方使用。
shell 里使用 ln 命令即可,系统调用为 link()
硬链接在文件上才能做,文件系统无法区分谁是先创建的,就和两个指针指向同一个地址一样。因此不能链接目录,也不能跨文件系统。
因此文件系统里还有一种链接为软链接,这是真快捷方式。linux 允许嵌套,但是有跳转上限。
ln -s ,系统调用为 syslink()
还有个机制是可以链接为环的。这样的话目录就不是一个树了,就是一个目录图。
文件api(系统调用)
最后更新于
这有帮助吗?