
3.设备驱动程序
前面解决了什么是 IO 设备的问题。我们可以把设备想象成一组寄存器,以及寄存器基础上的一个设备通信协议,能够实现处理器和设备之间的数据交换:数据可以小到一个字符 (串口),也可以大到程序和海量的数据 (GPU)。
硬件上,计算机系统都通过导线连接。
很自然的问题是,如果操作系统上的程序想要访问设备,就必须把设备抽象成一个进程可以使用系统调用访问的操作系统对象,也就是设备驱动程序和文件系统:
这部分回答的问题,操作系统如何使应用程序能访问这些设备?
什么是设备驱动程序?
Linux 设备抽象
设备驱动程序的第一个直观接触,新买了显卡,装驱动。
3. 设备驱动程序
IO 设备的抽象
IO 设备模型:一个能与 CPU 交换数据的接口/控制器。寄存器映射到地址空间。
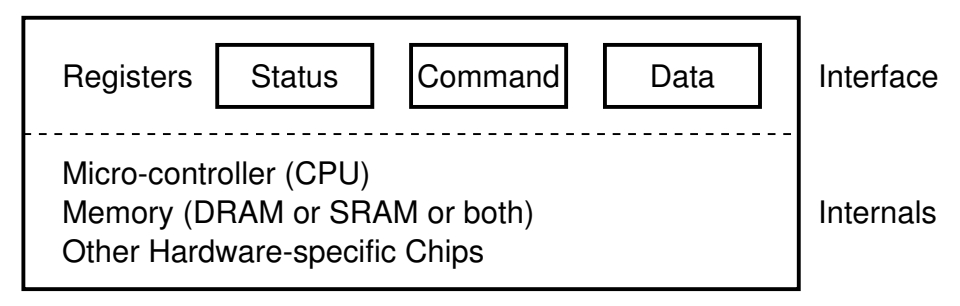
这是个很好的想法。更好的想法是操作系统应该把设备抽象成操作系统对象,比如字符终端、磁盘、都应该是对象,对象可以执行一些操作,这样用户访问设备就可以用相同的接口,不用再看地下的每个设备都不一样的寄存器。
如果要把 IO设备抽象成操作系统对象的话,要考虑一些东西。给对象实现什么样的操作,也很显然
I/O 设备的主要功能:输入和输出,。终端设备、磁盘都是这样,最基本的要求能读能写,因此 linux 里的基本抽象“能够读 (read) 写 (write) 的字节序列 (流或数组)”,byte stream,即无法回溯,读到了就读到了,常见的设备都满足这个模型
终端/串口 - 字节流
打印机 - 字节流 (例如 PostScript 文件)
硬盘 - 字节数组 (按块访问)
GPU - 字节流 (控制) + 字节数组 (显存)
操作系统:设备 = 支持各类操作的对象 (文件)
read - 从设备某个指定的位置读出数据
write - 向设备某个指定位置写入数据
ioctl - 读取/设置设备的状态
多了个 ioctl 系统调用,可以去看这个系统调用的 man page,设备抽象成了操作系统里的对象就可以用描述符去指向,这就可以把设备当作文件打开,读写或者做操作。
设备驱动程序
一个设备接入计算机,不一定马上就能很好的工作,越复杂的设备越是如此,操作系统可能没有提供默认的驱动程序。如新装系统缺网卡驱动、显卡驱动。设备驱动程序的第一个直观接触,新买了显卡,装驱动。
驱动实际上就是设备和操作系统对象之间的桥梁。
driver 就是操作系统里的一份代码,这个代码知道 IO 设备每个具体的寄存器的含义,同时可以把对设备的 read、write、ioctl 翻译成对寄存器的操作。和 shell 类似,把命令翻译成系统调用序列。
设备驱动程序直接去访问设备的每个寄存器,严格按照约定好的方式,操作寄存器。
所以所谓的设备驱动程序就是一段普通的代码,甚至未必真的需要一个设备。
比如 linux 里 /dev 里面有些好玩的设备,这里面的文件,设备也是文件。可以看到之类的文件类型 b 或者 c,即字符设备、块设备。
还有三个 stdin stdout stderr 软链接到了,访问自己进程的这三个东西,有的时候给命令行传入这个文件。此外还有很多 tty,terminal,可以试一下,echo hello > /dev/tty 会输出到当前终端。如果打开两个终端,用 tty 看一下终端号,可以向另一个终端输出内容。所以操作系统里没有什么神秘的,每个IO设备就是一个普通的对象,只要有 fd 能指向这个对象,就能做操作。
此外一些虚拟设备
/dev/pts/[x]pseudo terminalcat /dev/zero | head --bytes 512 > a.txt零设备/dev/null黑洞,可以想象如何实现驱动,有个write,直接返回 count 就好了/dev/random,/dev/urandom随机数生成器
可以去看看这些操作的系统调用。
简化的设备驱动
简化的设备模型,方便理解工作机制。
简化的假设
设备从系统启动时就存在且不会消失
支持读/写两种操作
在无数据或数据未就绪时会等待 (P 操作)
typedef struct devops {
int (*init)(device_t *dev);
int (*read) (device_t *dev, int offset, void *buf, int count);
int (*write)(device_t *dev, int offset, void *buf, int count);
} devops_t;这部分代码和真实的linux 内核驱动很像。
I/O 设备看起来是个 “黑盒子”
写错任何代码就 simply “not work”
设备驱动:Linux 内核中最多也是质量最低的代码
因为不断有新的设备想要接入到电脑上。每个厂商造出了新设备都希望再内核里加入驱动代码。
这样抽象的缺点
概念上简单,实际上很复杂,设备最基本的功能就是读写数据,不管是 nvme 的磁盘还是键盘鼠标。但是除了读写设备,还提供了各种各样五花八门的功能。
比如高端键盘,会给个 RGB,如果想让等可配置,应该把代码实现在哪里呢?所有和设备控制功能相关的东西都到 ioctl 了,这就导致这部分代码变得无比的大。
看起来干净简单、利落的抽象,把所有的复杂性都塞进实现里了。

例子
打印机的打印质量/进纸/双面控制、卡纸、清洁、自动装订……
一台几十万的打印机可不是那么简单 😂
键盘的跑马灯、重复速度、宏编程……
磁盘的健康状况、缓存控制……
这都是复杂性,看起来简单抽象背后一定有东西会膨胀。
举个例子终端。前面熟悉了 tty 的命令,用 stty -a 的命令,能看到 行列数,甚至可以配置 ctrl+c 是可配置的,还有很多终端的行为控制。包括密码,回显都可以配置。也有很多 api 可以访问终端相应的选项,比如 isatty 去问 fd 是不是个终端。以及一整套的 termios 可以去控制终端,相当多的东西在里面。
4. linux 的设备驱动
一个真正的设备驱动程序
一个真正的小的设备驱动。
当我们要给一个设备编写一个驱动程序的时候,所谓的设备,就是支持 read write 的操作系统对象,我们实现驱动就是去实现这样一个对象。
用内核模块做这么个事情,内核模块是一段可以被内核动态加载的代码。
驱动代码里面实现了 file_operations , 所以谈 everything is file 的时候,设备也是 file,所以为设备写驱动程序,只要实现 文件操作就好了,不一定要有真的设备,当然可以有真的时候,在内存映射地址有寄存器,就可以真的去操作设备了。
驱动程序代码会编译成一个类似 .so 的动态链接的东西,.ko 最终运行在内核上,这个动态链接库有一些额外的支持。
写好驱动程序,编译出动态加载模块后,可以用 insmod 加载到内核中,在 /dev/ 中就会多两个设备,可以读可以写。会执行我们的代码。
驱动代码输出使用了 printk ,操作系统内核日志来查看内容 tail -f /var/log/kernel.log
这是一个小 demo,展示了驱动原理,从终端到显卡,功能都是类似的。设备本质上是一个可以和用户交换数据的一个东西,所以设备驱动程序实现的就是把数据丢到设备驱动程序里,然后设备驱动程序吧数据丢到设备里。同样的,设备驱动程序也可以从设备里拉数据,然后送回到应用,使用 copy_to_user 和 copy_from_user
所以 everything is a file。设备驱动就是实现了 struct file_operations 的对象
把文件操作翻译成设备控制协议
调用到设备实现的 file_operations
更多的 file_operations
实际上设备驱动程序可以实现的操作是很多的,
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*flock) (struct file *, int, struct file_lock *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);可以看到很多我们熟悉的东西,如 mmap,flush,lock,
以及两个 ioctl 函数,都是历史原因遗留下来的。
存储设备的抽象
磁盘 (存储设备) 的访问特性,SSD HDD 的驱动程序,很自然的也会把字节序列抽象成 read write 两个函数。如果这样抽象并不好。一个磁盘可能有 1TB 那么大,而且磁盘是在各个应用程序直接共享的。这就好比把一个共享内存丢给了线程,共享了以后,自己去实现同步?这对应用程序来说,这是个灾难,磁盘是所有程序共享的,所以和终端这种独占访问的设备不太一样的。
总的来说,单单驱动程序把磁盘抽象成一个可读可写的字节序列是不够的,我们需要一个更高级的抽象。
linux 如何解决这个问题?一些磁盘的访问特性
以数据块 (block) 为单位访问
传输有 “最小单元”,不支持任意随机访问
最佳的传输模式与设备相关 (HDD v.s. SSD)
大吞吐量
使用 DMA 传送数据
应用程序不直接访问
访问者通常是文件系统 (维护磁盘上的数据结构)
大量并发的访问 (操作系统中的进程都要访问文件系统)
对于一个闪存盘来说,哪怕要写一个字节,也要读出一块,改掉,然后再整块写进去。不支持任意的随机访问,而且最佳的传输模式和设备是相关的,。磁盘是共享的,所有的应用程序都想访问磁盘,应用程序不直接访问磁盘,访问的是文件系统。linux 在文件系统和底层设备之间构建了一整个存储的抽象层。
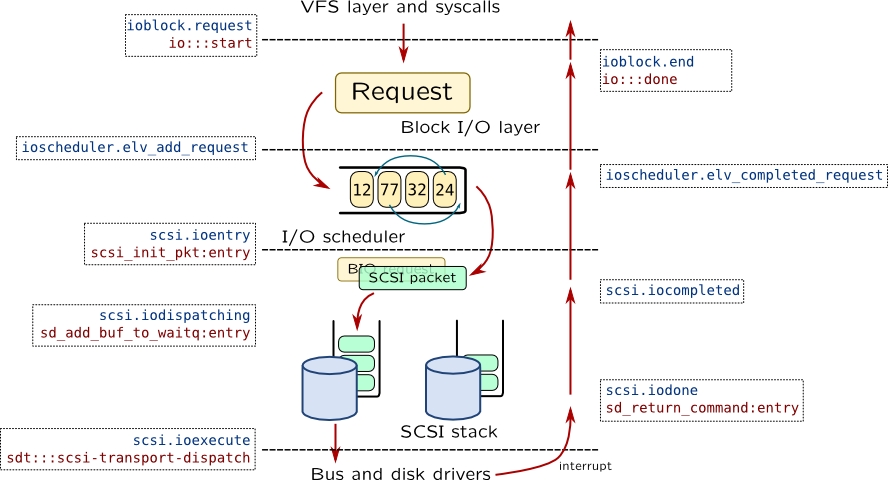
linux 做了一个 linux block io layer,上层的应用程序和文件系统的实现可以给 block io 层提交 request,Block IO Layer 有个队列,这个队列最终会给磁盘的驱动程序。
有了这个机制以后,就可以在块设备的基础上构建今天看到的文件系统了。
存储设备的虚拟化
简单回顾一下,从1bit存储开始,到设备驱动程序把设备抽象成一个可读可写的东西,然后再经过一个软件层变成 block 的可读可写,在这个上面,就能实现文件系统和存储设备的虚拟化。
文件系统最重要的目的是实现磁盘设备在应用程序之间的共享。磁盘中存储了很多数据,
程序数据
可执行文件和动态链接库
应用数据 (高清图片、过场动画、3D 模型……)
用户数据
文档、下载、截图
系统数据
Manpages
配置文件 (/etc)
文件系统了存储了计算机世界的全部,所以,字节序列并不是磁盘的好抽象。不能像线程一样,丢给一块共享内存自己来玩,这样并不是一个负责任的抽象,让所有应用共享磁盘,一个程序有个 bug 可能操作系统就给了。
文件就是一个字节数组。文件就是操作系统里的一个对象。文件是不是又回到了一种虚拟磁盘的感觉。
文件是个字节数组,磁盘也是个字节数组,所以文件系统很有意思的是,他是个磁盘的虚拟化,这和处理器、内存的虚拟化有点点像。1个处理器,按时间分片;一个物理内存,搞出许多虚拟内存空间;物理磁盘很大,分成许多个虚拟磁盘(文件)
所以文件系统的设计目标:
1.提供合理的 API 使多个应用程序能共享数据
2.提供一定的隔离,使恶意/出错程序的伤害不能任意扩大
所以对磁盘的虚拟化,“存储设备 (字节序列) 的虚拟化”
磁盘 (I/O 设备) = 一个可以读/写的字节序列
虚拟磁盘 (文件) = 一个可以读/写的动态字节序列
命名管理
虚拟磁盘的名称、检索和遍历
数据管理
std::vector (随机读写/resize)
文件系统里有好多文件,每个文件都是字节序列,都是虚拟磁盘。我们还有一个问题,即如何根据文件的名字找到这些文件。如果说文件就是操作系统里的对象的话,编号当然是可以的,如果应用程序用编号来访问这是不太好的。所以需要有文件的命名管理、遍历检索功能。这就是文件系统,概念很直观。
计算机从一个操作系统支持一个应用程序变到支持好多个应用程序一个非常自然的抽象,多个应用程序肯定有许多东西是要共享的,比如配置文件,动态链接库,我们希望只要给个名字,就能找到文件。
linux 里有文件描述符,最早就是从文件系统来的,。既然是虚拟的磁盘,文件也可以提供像 mmap 这样的调用,把虚拟磁盘的一部分映射到地址空间。当映射的时候,操作系统几乎什么都没做,操作系统把这部分标记了,当有个指针操作这部分数据,会产生缺页异常,然后进程就会经过一整个文件继续的实现,翻译成对磁盘的读写。
这里还有更多的小细节,比如如果映射的长度超过文件的大小,会发生一个 SIGBUS 信号,有一个 bus error。
文件访问的游标(偏移量)
文件的访问都是带偏移量的,文件的读写自带 “游标”,这样就不用每次都指定文件读/写到哪里了
read(fd, buf, 512); - 第一个 512 字节
read(fd, buf, 512); - 第二个 512 字节
lseek(fd, -1, SEEK_END); - 最后一个字节
虽然文件系统是一个虚拟的磁盘,但是有一个像指针的东西的,方便程序员的使用。
但是偏移量的管理也不简单。一个问题,文件描述符在 fork 时会被子进程继承。那么父子进程应该共用偏移量还是各自持有偏移量?这决定了 offset 存储在哪里。
考虑应用场景,父子进程同时写入文件,希望各自持有偏移量,如果希望共享偏移量(如写log),那么操作系统来管理偏移量。
linux 的设计是共享偏移量,但是操作系统任然会保证 write 的原子性。
目录的管理
linux 目录挂载
什么是文件夹?
虚拟磁盘(文件)那么多,怎么找到想要的?
如果按照名字编到一起,找一个文件是很不容易的。
这里用到了信息的局部性,类似图书馆分类。思想是类似的,先尽可能的把大类型的分开。
组成一个目录树。
树总得有个根结点,即文件系统的 “根”。
Windows: 每个设备 (驱动器) 是一棵树
C:\ “C 盘根目录”
C:\Program Files,
C:\Windows,
C:\Users,
...
优盘分配给新的盘符
为什么没有 A:, B:?,AB是软盘,时代的
设计很好,简单、粗暴、方便,每个驱动器就是根,驱动器就以为着局部性,如系统盘、文件盘、软键盘,但带来的麻烦 game.iso 一度非常麻烦……
想把光盘里的东西打开作为文件系统的一部分就比较麻烦。
unix 用了一个不一样的设计,整个 unix 只有一个根。即 / 这就麻烦了,U 盘怎么办呢?unix 给出的答案,挂载。
unix 可以把设备里的目录加到目录树的任意位置。这既是 unix 管理目录树的方式。一开始这个根可以啥也没有,东西越挂越多。目录拼接的操作。这就是 unix 管理文件系统目录树的方式,一开始可以只有 / ,这个是个空的,啥也没有,我们可以把东西挂载上去。
在安装 linux 的时候,会让指定一个挂载点,(mount point),一开始可能不知道这个概念。
在 /etc/fstab 文件描述了开机的时候,设备挂载的方式。
在这种机制下,/ /home /var 可以是独立的磁盘设备
mount 命令是通过一个 mount 的系统调用实现的。
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);真正 linux 的启动
前面,最小的 linux ,里面的文件系统,就我们用的区别很大。文件特别少,甚至 /dev 里都没有设备。这个 linux-minimal 运行在 initramfs 模式。这个文件系统是个不完整的文件系统,根目录下缺了特别多的东西,。
即,一开始的文件系统啥也没有,东西特别少,我们通过 mount 慢慢的构建起一整个完整的东西。
我们的 linux 世界,在 initramfs 模式下,去扫描系统里的存储设备,找到能够启动的磁盘,比如从 sda 启动
再执行更多的命令,在 initramfs 里面,可以把整个个文件系统挂载到 /mnt,然后执行 switch_root,然后我们就有了一个新的完整的文件系统。旧的部分会自动回收掉,这就真正进入了我们见到的 Linux。
文件的挂载
linux 里我们可以把一个磁盘镜像挂载上去,映射到文件系统上的目录里。对于一个文件的挂载,引入了一个微妙的循环
文件 = 磁盘上的虚拟磁盘
挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘 🤔
Filesystem Hierarchy Standard (FHS)
在第一次看到 linux 的目录树是绝望的,用过 windows 在来看 linux 的文件系统都不知道在干嘛。事实上这个东西是有标准的。
所有的 linux 都遵循 linux FHS,这是一套通用的语言。广泛使用的东西,大家共同遵守就好了。
目录管理
有了这个目录的结构以后,我们就可以对目录做一些操作了,用文件系统 API 去管理一下这个目录,比如创建文件夹、删除文件夹等。
mkdir
rmdir
在 pstree 的时候就进行过这些操作。
这里主要了解一些比较有趣的系统功能。
硬链接。就是做一个别名。
ln hello.txt world.txt
这种链接操作系统都无法区分哪个是先创建的,哪个是后创建的,无法区分,文件系统中的文件编号都是一样的。
所以改任何一个文件,另一个也会改。这两个文件完全不可区分。
这种硬链接的需求:系统中可能有同一个运行库的多个版本
libc-2.27.so, libc-2.26.so, ...
还需要一个 “当前版本的 libc”
程序需要链接 “libc.so.6”,能否避免文件的一份拷贝?
这是文件系统提供的功能。一个惊人的事实:文件系统里面所有的文件都是硬链接的。linux 世界里没有文件,只有链接。我们可以用 unlink 来删除一个文件。
此外,我们还可以为一个文件创建快捷方式。即跳转的方式,比如给上级目录起个名字。使用 ln -s
这个文件甚至可以不存在,只是访问呢的时候会出错。在这个机制下,文件系统允许我们创建一个回路。
----
老版本未总结。
不管是什么设备,操作系统看来就是一组寄存器,以及一组协议。
每个设备的协议都是不一样的。比如说打印机,现在的新打印机都是一台计算机了,可以联网。
设备具有复杂性。如果直接把设备的寄存器暴露给应用程序时很危险的,应用程序直接和设备做底层的交互是很危险的。
我们需要对设备做抽象。键盘、鼠标、磁盘,这些都需要做抽象。这样的话应用程序就不需要访问这些寄存器了,这样的话应用程序就尽可能用一个统一的方式来、统一的 API 来操作了。
所以设备驱动程序最核心的想法是把IO设备共有的功能提取出来,使得应用程序可以使用同样的接口,(不需要知道寄存器的编号之类的复杂细节)。
这就回到 IO设备的抽象,什么叫 IO 设备。input output device。即最重要的两个功能就是输入输出,不管是什么设备到最后,最核心的就这两个事情。
I/O 设备的主要功能:输入和输出
几乎所有的设备都满足这些模型。设备有两种,char device、block device。
字符设备位字节流,他不像RAM读同一个位置同一个值,字符设备有点像管道。
块设备像一个很大字节的数组,按照一块一块的方式读写。
问题来了,GPU 是什么样的设备。GPU 有显存,用字节数组来抽象,但是不需要按块访问;此外 GPU 还有控制的一部分,比如说要设置分辨率,这个功能可以用字节流,也可以和寄存器通信来实现。
这些所有的五花八门的设备,还用什么样的抽象呢?
提供这些操作
read
write 向某个设备写
ioctl 读取设置设备的状态
不管是什么设备,抽象都是 read、write、ioctl,那么什么是设备驱动程序呢?是我们位设备建立的模型代码,设备说到底还是寄存器,我们需要一段代码把 read、write、ioctl 翻译成设备寄存器能听懂的东西。
设备驱动就是把通用 API 变成五花八门的设备寄存器的操作。driver,和 shell 挺像的,把命令翻译成系统调用。
人发出命令->shell->系统调用->驱动程序
例子 /dev/ 中的对象。 比方说,生成随机数的设备
当然设备有真有假,比如说,null 设备,如果程序的输出不想要了,就可以重定向到 这里
echo hell > /dev/nullyes 命令,重定向到这里,可以通过 strace 来看看。
null 是最简单的一个设备驱动程序,他收到任何write请求直接返回就好了,丢掉所有写的数据,如果是read就立即返回 0。
还有个 zero 零设备。
还有一些模拟设备,比如tty,。
当然也有很多实际设备。
学习用的操作系统里的设备驱动,可以假设设备从操作系统启动时就存在且不会消失。(对比即插即用设备),这样就没什么好控制的了,就是字节流或者块设备。
但是,就是因为这种抽象,设备驱动就变成了一件复杂的事情。设备是非常非常复杂的,设备驱动在操作系统内核里,只要指针乱跑了,对内核的破坏都是毁灭级别的。
有时候硬件厂商的手册写的也不清楚,。所以设备驱动时 linux 内核中最多也是质量最低的代码。寄存器的含义有时候只有制造他的人知道。
windows vista 尝试把大部分驱动程序移动到用户空间,linux 现在也在努力做这个事情。
复杂性的例子,键盘,现在有了带RGB的键盘,甚至可以显示图画。我们正常用键盘当作字节流,那么这个灯则么办。除了设备的主要功能之外,其他的功能时复杂性的来源。尤其是设备的附加功能和配置。更多例子
印机的打印质量/进纸/双面控制、卡纸、清洁、自动装订……
一台几十万的打印机可不是那么简单 😂
键盘的跑马灯、重复速度、宏编程……
磁盘的健康状况、缓存控制……
这些额外的功能,都依赖于 ioctl ,看这个函数的手册,可以知道此函数可以传入任意数据给操作系统内核,也就是说IO设备的控制时直接暴露给应用程序的,这带来了很大的麻烦,这使得一个 ioctl 在内核里可能有1000w行代码。
举个例子,终端。
比如说 ls 的输出打印到终端上,vi编辑一个文件也是在终端上。终端支持很多比较炫酷的功能,python3 -m rich ,终端如何显示比较炫酷的内容呢?回顾模拟数码管的例子,输出到终端的东西有一些转义序列。tty -all 可以显示终端所有的设置,看手册,可以看到修改这些设置全是通过 ioctl 实现的。
最后更新于
这有帮助吗?